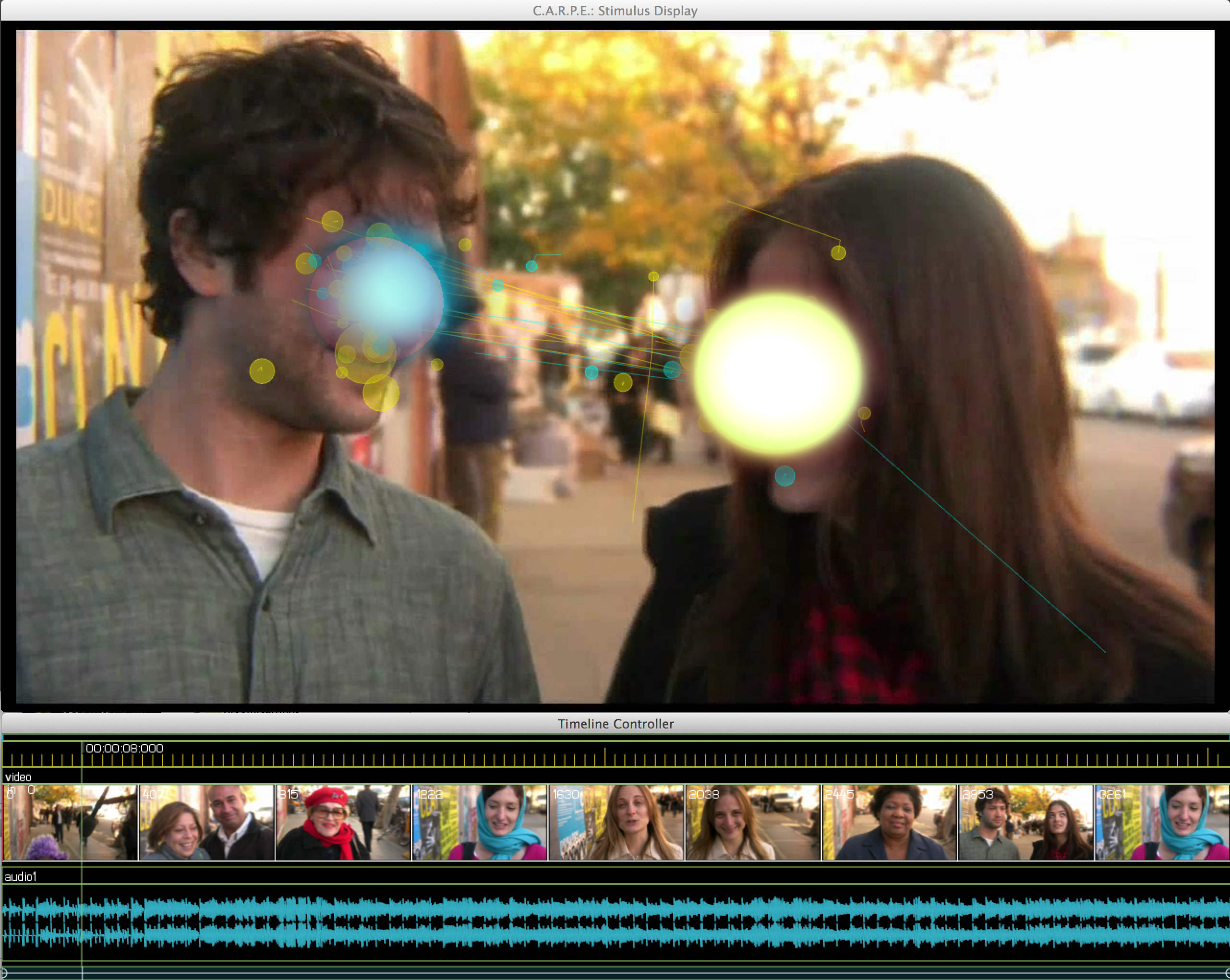
Original video still without eye-movements and heatmap overlay copyright Dropping Knowledge Video Republic.
From 2008 – 2010, I worked on the Dynamic Images and Eye-Movements (D.I.E.M.) project, led by John Henderson, with Tim Smith and Robin Hill. We worked together to collect nearly 200 participants eye-movements on nearly 100 short films from 30 seconds to 5 minutes in length. The database is freely available and covers a wide range of film styles form advertisements, to movie and music trailers, to news clips. During my time on the project, I developed an open source toolkit, C.A.R.P.E. to complement D.I.E.M., or Computational Algorithmic Representation and Processing of Eye-movements (Tim’s idea!), for visualizing and processing the data we collected, and used it for writing up a journal paper describing a strong correlation between tightly clustered eye-movements and the motion in a scene. We also output visualizations of our entire corpus on our Vimeo channel. The project came to a halt and so did the visualization software. I’ve since picked up the ball and re-written it entirely from the ground up.
The image below shows how you can represent the movie, the motion in the scene of the movie (represented in … Continue reading...